 I had the chance to speak at the OpenStorage Summit a couple of weeks ago about RAID-Z (the ZFS implementation of RAID). The talk was an accumulation of blog posts and articles written by me and others as well as quite a bit of new material that’s been building up. The talk was an overview of the history of RAID-Z, the strengths and weaknesses that have emerged, and a look towards the challenges ahead for ZFS and RAID with some possible solutions and mitigating factors. Thanks to Nexenta for putting the conference together; questions or comments are very welcome.
I had the chance to speak at the OpenStorage Summit a couple of weeks ago about RAID-Z (the ZFS implementation of RAID). The talk was an accumulation of blog posts and articles written by me and others as well as quite a bit of new material that’s been building up. The talk was an overview of the history of RAID-Z, the strengths and weaknesses that have emerged, and a look towards the challenges ahead for ZFS and RAID with some possible solutions and mitigating factors. Thanks to Nexenta for putting the conference together; questions or comments are very welcome.
A key component of the ZFS Hybrid Storage Pool is Logzilla, a very fast device to accelerate synchronous writes. This component hides the write latency of disks to enable the use of economical, high-capacity drives. In the Sun Storage 7000 series, we use some very fast SAS and SATA SSDs from STEC as our Logzilla &mdash the devices are great and STEC continues to be a terrific partner. The most important attribute of a good Logzilla device is that it have very low latency for sequential, uncached writes. The STEC part gives us about 100μs latency for a 4KB write — much much lower than most SSDs. Using SAS-attached SSDs rather than the more traditional PCI-attached, non-volatile DRAM enables a much simpler and more reliable clustering solution since the intent-log devices are accessible to both nodes in the cluster, but SAS is much slower than PCIe…

DDRdrive X1
Christopher George, CTO of DDRdrive was kind enough to provide me with a sample of the X1, a 4GB NV-DRAM card with flash as a backing store. The card contains 4 DIMM slots populated with 1GB DIMMs; it’s a full-height card which limits its use in Sun/Oracle systems (typically half-height only), but there are many systems that can accommodate the card. The X1 employs a novel backup power solution; our Logzilla used in the 7000 series protects its DRAM write cache with a large super-capacitor, and many NV-DRAM cards use a battery. Supercaps can be limiting because of their physical size, and batteries have a host of problems including leaking and exploding. Instead, the DDRdrive solution puts a DC power connector on the PCIe faceplate and relies on an external source of backup power (a UPS for example).
Performance
I put the DDRdrive X1 in our fastest prototype system to see how it performed. A 4K write takes about 51μs — better than our SAS Logzilla — but the SSD outperformed the X1 at transfer sizes over 32KB. The performance results on the X1 are already quite impressive, and since I ran those tests the firmware and driver have undergone several revisions to improve performance even more.
As a Logzilla

While the 7000 series won’t be employing the X1, uses of ZFS that don’t involve clustering and for which external backup power is an option, the X1 is a great and economical Logzilla accelerator. Many users of ZFS have already started hunting for accelerators, and have tested out a wide array of SSDs. The X1 is a far more targeted solution, and is a compelling option. And if write performance has been a limiting factor in deploying ZFS, the X1 is a good reason to give ZFS another look.
The other day I posted about a prototype I had created that adds a gzip compression algorithm to ZFS. ZFS already allows administrators to choose to compress filesystems using the LZJB compression algorithm. This prototype introduced a more effective — albeit more computationally expensive — alternative based on zlib.
As an arbitrary measure, I used tar(1) to create and expand archives of an ON (Solaris kernel) source tree on ZFS filesystems compressed with lzjb and gzip algorithms as well as on an uncompressed ZFS filesystem for reference:
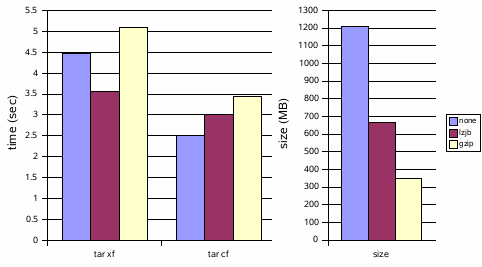
Thanks for the feedback. I was curious if people would find this interesting and they do. As a result, I’ve decided to polish this wad up and integrate it into Solaris. I like Robert Milkowski’s recommendation of options for different gzip levels, so I’ll be implementing that. I’ll also upgrade the kernel’s version of zlib from 1.1.4 to 1.2.3 (the latest) for some compression performance improvements. I’ve decided (with some hand-wringing) to succumb to the requests for me to make these code modifications available. This is not production quality. If anything goes wrong it’s completely your problem/fault — don’t make me regret this. Without further disclaimer: pdf patch
In reply to some of the comments:
UX-admin One could choose between lzjb for day-to-day use, or bzip2 for heavily compressed, “archival” file systems (as we all know, bzip2 beats the living daylights out of gzip in terms of compression about 95-98% of the time).
It may be that bzip2 is a better algorithm, but we already have (and need zlib) in the kernel, and I’m loath to add another algorithm
ivanvdb25 Hi, I was just wondering if the gzip compression has been enabled, does it give problems when an ZFS volume is created on an X86 system and afterwards imported on a Sun Sparc?
That isn’t a problem. Data can be moved from one architecture to another (and I’ll be verifying that before I putback).
dennis Are there any documents somewhere explaining the hooks of zfs and how to add features like this to zfs? Would be useful for developers who want to add features like filesystem-based encryption to it. Thanks for your great work!
There aren’t any documents exactly like that, but there’s plenty of documentation in the code itself — that’s how I figured it out, and it wasn’t too bad. The ZFS source tour will probably be helpful for figuring out the big picture.
Update 3/22/2007: This work was integrated into build 62 of onnv.
Technorati Tags: ZFS OpenSolaris